AI Is Writing Code Now — Should Developers Actually Be Worried?
A balanced look at tools like GitHub Copilot, what they can't do, and where human skill still wins.
Let me be direct: I've been using GitHub Copilot, Claude, and ChatGPT in my daily development workflow for over a year. I've watched colleagues swear by them, watched others dismiss them entirely, and watched a few silently panic. The question "will AI replace developers?" has become the most anxiety-producing sentence in our industry — and I think most discussions around it are getting the framing completely wrong.
The real question isn't whether AI can write code. It clearly can. The question is: what does writing code actually mean?
Code is the last 20% of the job. The first 80% — understanding what to build, why to build it, and whether it's the right thing at all — is still entirely human territory.
What AI Coding Tools Are Actually Good At
Let's be fair. Tools like GitHub Copilot, Cursor, and similar AI assistants are genuinely impressive for a specific category of tasks. If you've ever groaned while writing the same boilerplate CRUD operations for the fifth time, or wasted twenty minutes searching for the exact syntax of a date formatting function, you already know the value proposition.
Here's where they shine without apology:
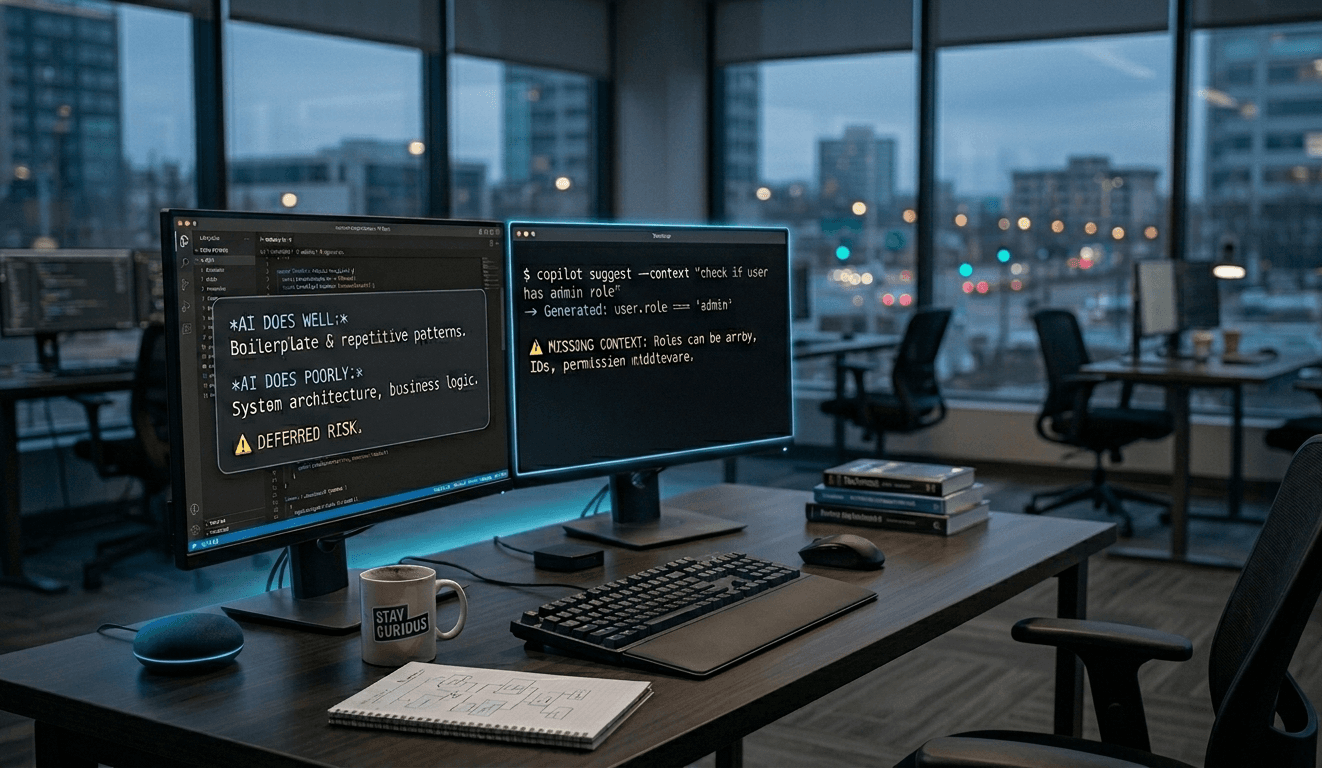
*AI DOES WELL*
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
◆ System architecture decisions
◆ Debugging subtle race conditions
◆ Understanding business requirements
◆ Security threat modelling
◆ Performance at scale reasoning
◆ Knowing when not to build
◆ Cross-team communication
A GitHub study found that developers using Copilot completed certain coding tasks up to 55% faster. That's not a small number. For the right task, these tools are a genuine multiplier. Accepting that honestly is important — pretending they don't work is how you become the developer who gets left behind.
`// You type: "fetch users, filter active, sort by name" // Copilot writes the rest — instantly, correctly:
const getActiveUsersSorted = async (): Promise<User[]> => { const users = await fetchUsers(); return users .filter(user => user.isActive) .sort((a, b) => a.name.localeCompare(b.name)); };
// Simple, correct, idiomatic. Zero thinking required. // This is exactly what it's for.`
The Confidence Problem
Here is the thing nobody tells you in the excitement around these tools: AI writes wrong code with the same confidence it writes right code.
This is not a small caveat. It's the central issue. When a junior developer makes an error, there are usually visible signs — hesitation, a comment asking for review, an obvious logic gap. When Copilot makes an error, it often looks exactly like correct, idiomatic code. The function has the right shape. The variable names are sensible. The structure is clean. And it's subtly, dangerously wrong.
`$ copilot suggest --context "check if user has admin role" → Generated: user.role === 'admin'
⚠ What it missed: · Roles can be an array, not a string · Case sensitivity varies by system · Your app uses role IDs, not strings · This bypasses your permission middleware entirely
→ Result: a security vulnerability that looks fine on review`
The risk compounds when developers — especially those earlier in their careers — treat AI output as authoritative. The tool has no model of your system. It doesn't know your database schema, your permission structure, your deployment environment, or the three decisions you made in a meeting two weeks ago that changed the data model. It knows patterns. Patterns and your specific context are not the same thing.
What AI Still Cannot Do
Let's get specific, because the limitations aren't vague hand-waving — they're structural.
-
- It cannot understand your business. The most important decisions in software development are rarely technical. Should we build this feature at all? What does "done" actually mean to the stakeholder? What will users actually do versus what they say they'll do? These questions require human judgment, context, and often uncomfortable conversations. No LLM sits in your sprint planning meeting.
-
- It cannot reason about novel systems. AI tools excel in domains richly represented in their training data — React, Python, common APIs. But the moment you're working with a proprietary internal framework, a legacy system with unusual constraints, or a new architecture pattern that emerged six months ago, the quality degrades sharply. The model starts hallucinating APIs that don't exist, functions that look right but aren't.
-
- It cannot debug what it doesn't understand. Real production debugging is detective work. It requires forming and testing hypotheses, understanding how two systems interact under specific conditions, reading logs with intuition about what matters. AI can suggest likely causes. It cannot reason about your specific production environment at 2am when the memory leak only appears under load.
-
- It cannot own the outcome. When the code ships and something breaks — the developer is responsible. That accountability loop is inseparable from the judgment loop. The developer who can't explain why their code does what it does isn't a developer using a tool; they're a proxy for one.
What AI Coding Tools Are Actually Good At
Let's be fair. Tools like GitHub Copilot, Cursor, and similar AI assistants are genuinely impressive for a specific category of tasks. If you've ever groaned while writing the same boilerplate CRUD operations for the fifth time, or wasted twenty minutes searching for the exact syntax of a date formatting function, you already know the value proposition.
Here's where they shine without apology:
*AI DOES WELL*
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
◆ System architecture decisions
◆ Debugging subtle race conditions
◆ Understanding business requirements
◆ Security threat modelling
◆ Performance at scale reasoning
◆ Knowing when not to build
◆ Cross-team communication
A GitHub study found that developers using Copilot completed certain coding tasks up to 55% faster. That's not a small number. For the right task, these tools are a genuine multiplier. Accepting that honestly is important — pretending they don't work is how you become the developer who gets left behind.
`// You type: "fetch users, filter active, sort by name" // Copilot writes the rest — instantly, correctly:
const getActiveUsersSorted = async (): Promise<User[]> => { const users = await fetchUsers(); return users .filter(user => user.isActive) .sort((a, b) => a.name.localeCompare(b.name)); };
// Simple, correct, idiomatic. Zero thinking required. // This is exactly what it's for.`
The Confidence Problem
Here is the thing nobody tells you in the excitement around these tools: AI writes wrong code with the same confidence it writes right code.
This is not a small caveat. It's the central issue. When a junior developer makes an error, there are usually visible signs — hesitation, a comment asking for review, an obvious logic gap. When Copilot makes an error, it often looks exactly like correct, idiomatic code. The function has the right shape. The variable names are sensible. The structure is clean. And it's subtly, dangerously wrong.
`$ copilot suggest --context "check if user has admin role" → Generated: user.role === 'admin'
⚠ What it missed: · Roles can be an array, not a string · Case sensitivity varies by system · Your app uses role IDs, not strings · This bypasses your permission middleware entirely
→ Result: a security vulnerability that looks fine on review`
The risk compounds when developers — especially those earlier in their careers — treat AI output as authoritative. The tool has no model of your system. It doesn't know your database schema, your permission structure, your deployment environment, or the three decisions you made in a meeting two weeks ago that changed the data model. It knows patterns. Patterns and your specific context are not the same thing.
What AI Still Cannot Do
Let's get specific, because the limitations aren't vague hand-waving — they're structural.
-
- It cannot understand your business. The most important decisions in software development are rarely technical. Should we build this feature at all? What does "done" actually mean to the stakeholder? What will users actually do versus what they say they'll do? These questions require human judgment, context, and often uncomfortable conversations. No LLM sits in your sprint planning meeting.
-
- It cannot reason about novel systems. AI tools excel in domains richly represented in their training data — React, Python, common APIs. But the moment you're working with a proprietary internal framework, a legacy system with unusual constraints, or a new architecture pattern that emerged six months ago, the quality degrades sharply. The model starts hallucinating APIs that don't exist, functions that look right but aren't.
-
- It cannot debug what it doesn't understand. Real production debugging is detective work. It requires forming and testing hypotheses, understanding how two systems interact under specific conditions, reading logs with intuition about what matters. AI can suggest likely causes. It cannot reason about your specific production environment at 2am when the memory leak only appears under load.
-
- It cannot own the outcome. When the code ships and something breaks — the developer is responsible. That accountability loop is inseparable from the judgment loop. The developer who can't explain why their code does what it does isn't a developer using a tool; they're a proxy for one.
Accountability and understanding are inseparable. You cannot be responsible for code you don't comprehend — which means blindly shipping AI output isn't fast delivery; it's deferred risk.
What AI Coding Tools Are Actually Good At
Let's be fair. Tools like GitHub Copilot, Cursor, and similar AI assistants are genuinely impressive for a specific category of tasks. If you've ever groaned while writing the same boilerplate CRUD operations for the fifth time, or wasted twenty minutes searching for the exact syntax of a date formatting function, you already know the value proposition.
Here's where they shine without apology:
*AI DOES WELL*
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
✦ Boilerplate & repetitive patterns
✦ Syntax recall across languages
✦ Generating unit test scaffolding
✦ Translating pseudocode to real code
✦ Documentation drafts from code
✦ Regex patterns and one-liners
✦ Autocomplete in known contexts
◆ System architecture decisions
◆ Debugging subtle race conditions
◆ Understanding business requirements
◆ Security threat modelling
◆ Performance at scale reasoning
◆ Knowing when not to build
◆ Cross-team communication
A GitHub study found that developers using Copilot completed certain coding tasks up to 55% faster. That's not a small number. For the right task, these tools are a genuine multiplier. Accepting that honestly is important — pretending they don't work is how you become the developer who gets left behind.
`// You type: "fetch users, filter active, sort by name" // Copilot writes the rest — instantly, correctly:
const getActiveUsersSorted = async (): Promise<User[]> => { const users = await fetchUsers(); return users .filter(user => user.isActive) .sort((a, b) => a.name.localeCompare(b.name)); };
// Simple, correct, idiomatic. Zero thinking required. // This is exactly what it's for.`
The Confidence Problem
Here is the thing nobody tells you in the excitement around these tools: AI writes wrong code with the same confidence it writes right code.
This is not a small caveat. It's the central issue. When a junior developer makes an error, there are usually visible signs — hesitation, a comment asking for review, an obvious logic gap. When Copilot makes an error, it often looks exactly like correct, idiomatic code. The function has the right shape. The variable names are sensible. The structure is clean. And it's subtly, dangerously wrong.
`$ copilot suggest --context "check if user has admin role" → Generated: user.role === 'admin'
⚠ What it missed: · Roles can be an array, not a string · Case sensitivity varies by system · Your app uses role IDs, not strings · This bypasses your permission middleware entirely
→ Result: a security vulnerability that looks fine on review`
The risk compounds when developers — especially those earlier in their careers — treat AI output as authoritative. The tool has no model of your system. It doesn't know your database schema, your permission structure, your deployment environment, or the three decisions you made in a meeting two weeks ago that changed the data model. It knows patterns. Patterns and your specific context are not the same thing.
What AI Still Cannot Do
Let's get specific, because the limitations aren't vague hand-waving — they're structural.
-
- It cannot understand your business. The most important decisions in software development are rarely technical. Should we build this feature at all? What does "done" actually mean to the stakeholder? What will users actually do versus what they say they'll do? These questions require human judgment, context, and often uncomfortable conversations. No LLM sits in your sprint planning meeting.
-
- It cannot reason about novel systems. AI tools excel in domains richly represented in their training data — React, Python, common APIs. But the moment you're working with a proprietary internal framework, a legacy system with unusual constraints, or a new architecture pattern that emerged six months ago, the quality degrades sharply. The model starts hallucinating APIs that don't exist, functions that look right but aren't.
-
- It cannot debug what it doesn't understand. Real production debugging is detective work. It requires forming and testing hypotheses, understanding how two systems interact under specific conditions, reading logs with intuition about what matters. AI can suggest likely causes. It cannot reason about your specific production environment at 2am when the memory leak only appears under load.
-
- It cannot own the outcome. When the code ships and something breaks — the developer is responsible. That accountability loop is inseparable from the judgment loop. The developer who can't explain why their code does what it does isn't a developer using a tool; they're a proxy for one.
Accountability and understanding are inseparable. You cannot be responsible for code you don't comprehend — which means blindly shipping AI output isn't fast delivery; it's deferred risk.